
As former U.S. Magistrate Judge Andrew J. Peck observed at Legalweek 2024, privilege logs that once spanned two or three pages now read “like little novels”—sometimes exceeding 10,000 entries.
Privilege review was never meant to resemble a Russian epic painstakingly drafted in Excel. Yet here we are: thousands of entries, endless debates over whether someone was acting in a legal or business capacity, and late nights parsing whether “please advise” meant legal advice—or was just polite corporate throat-clearing.
The Old Trick: “Just Run the Terms”
If this is an April Fool’s joke, it’s one the industry has been playing on itself for a long time.
For years, privilege has been treated like a keyword problem. Build a screen. Add attorney names. Sprinkle in terms like “legal,” “counsel,” and “privileged and confidential.” And if you’re lucky enough to have an experienced team like Page One, you can defensibly cut down the noise—filtering out obvious false positives like boilerplate email footers that say “privileged and confidential” but have nothing to do with legal advice.
But even the best keyword workflows can’t change the underlying reality: Privilege doesn’t live in keywords. It lives in relationships.
A draft agreement between two executives? Likely business.
The same draft, shared with in-house counsel for legal advice? Entirely different analysis.
The same counsel cc’d but giving no advice? Now we’re debating intent.
This is why, rather than relying on text triggers alone, aiR for Privilege evaluates privilege through roles, relationships, and purpose.
Not a Shortcut. Not an April Fool’s Trick. Just A Smarter, Multifaceted Approach.
aiR for Privilege brings together three forms of intelligence:
- Generative AI – analyzes and summarizes language.
- Machine learning – identifies and classifies communication patterns.
- Social network analysis – maps relationships between people and roles.
Individually, each technology captures only part of the privilege analysis. Together, however, they approximate reviewer judgment at scale—delivering a rapid first pass with high recall, precision, and transparent reasoning.
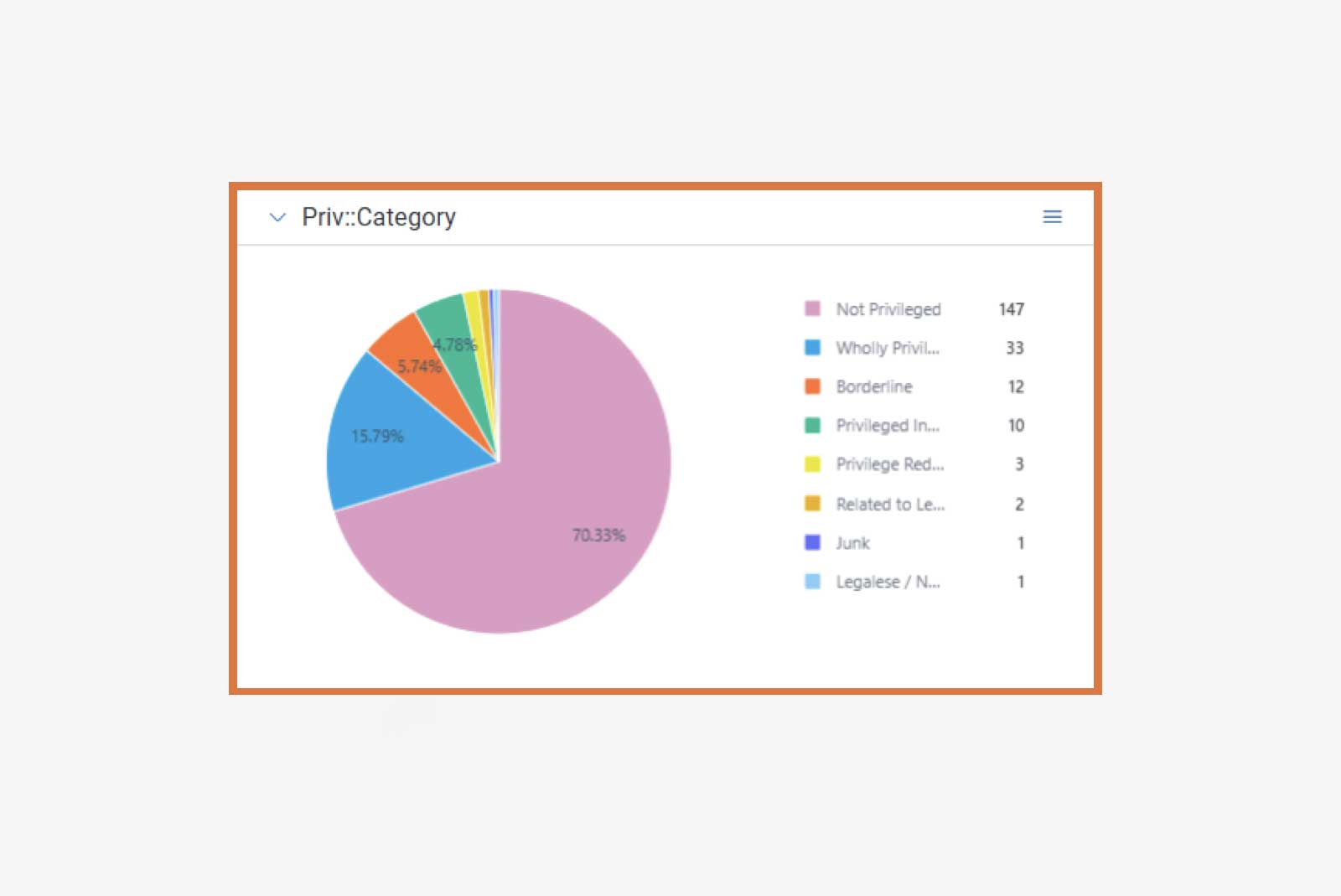
Defined prediction categories—Wholly Privileged, Privilege Redaction, Privileged Individual / No Privileged Content, and Borderline—add practical value. Teams can efficiently route sensitive documents to senior reviewers, prioritize quality control, and isolate likely redactions.
Each determination also includes: a plain-language Rationale explaining why a document was flagged—or not flagged—as privileged; Citations to the specific language supporting the assessment; Considerations surface potential counterarguments or areas of uncertainty; and a proposed Privilege Log Description.

These examples show how reviewers gain immediate visibility into the system’s reasoning, which can then be preserved in the review record to support defensibility if privilege determinations are later challenged.
This isn’t an April Fool’s automation gimmick. It’s industry changing structured intelligence applied to contextual legal decision-making.
The “Client Brain”: Not Sci-Fi, Just Smart Context
aiR for Privilege also includes what is often referred to as the “Client Brain”, which sounds like science fiction but functions more like institutional memory.
As part of its multifaceted approach, the Client Brain can learn from prior annotations within a specific client environment. For example, if a domain is identified as outside counsel, or an individual consistently acts in a legal role, that knowledge can be leveraged in future matters for that same client. The result is greater consistency, reduced repetitive annotation, and faster setup over time.
Importantly, data stored within the Client Brain is not used to train the underlying GPT models that power aiR for Privilege. That distinction is incredibly important. And if you’re not sure why, you should check out our recent blog on the discoverability of open generative AI platforms.
This Is the Part That Sounds Too Good to be True (It Isn’t)
The performance results are equally difficult to dismiss as a seasonal gag. In testing, legal teams are reporting meaningful improvements in both accuracy and efficiency. But we understand if you don’t take our word for it (it is April Fool’s after all!).
- “aiR for Privilege found over 5,000 privileged documents that contract reviewers had missed and highlighted exactly why they should be protected. It reduces our risk while driving massive savings. You can’t beat that.” – Head of eDiscovery, Fortune 100 Corporation [1]
- “aiR for Privilege is way more effective than manual review.” –Senior Discovery Attorney[2]
- “By automating repetitive tasks and leveraging past learnings, organizations can cut privilege review time by over 50%. For example, in one law firm’s test of aiR for Privilege, the team compared aiR’s results against human coding of 4,300 responsive documents. aiR for Privilege took only five hours total to set up, run, and validate, compared to 130 hours needed for manual review, with similarly impressive accuracy.” – White Paper: Relativity aiR for Privilege: A Step-by-Step Guide to AI that Solves the Privilege Problem[3]
The bottom line is this: aiR for Privilege is not an April Fool’s punchline. It is a transformational shift in how teams approach privilege review. It reduces risk, improves accuracy, speeds up workflows, and brings long‑overdue consistency to one of discovery’s most difficult tasks.
And there’s nothing foolish about that.
[1] https://relativity.com/resources/customers/fortune-100-relativity-air/
[2] https://www.relativity.com/one-with-everything/
[3] https://resources.relativity.com/relativity-air-for-privilege-guide-to-ai-white-paper-lp.html